Oliver W. Layton
I’m a computational cognitive neuroscientist.
I build neural models and design experiments that link perception, action, and behavior with the brain. The focus is on human navigation: what strategies and mechanisms in the primate brain make humans so capable when moving through dynamically changing, complex environments (e.g. driving through traffic, walking through Grand Central Terminal)? My approach treats perception and action as a single interactive process that evolves over time, in contrast to the traditional view of perception as the passive outcome of sensory processing. My goal is to leverage fundamental mechanisms that underlie perception and the control of self-motion to design better technology that emulates the primate brain.
I am currently a postdoctoral scholar working with Brett Fajen in the Cognitive Science Department at Rensselaer Polytechnic Institute (RPI) I received my Ph.D. in Cognitive and Neural Systems from Boston University in 2013. I developed neural models of self-motion perception and figure-ground segregation with Ennio Mingolla Arash Yazdanbakhsh, and Andrew Browning. My work culminated in a large-scale dynamical neural model that elucidates human perception during locomotion through realistic environments. In 2009, I graduated from Skidmore College with degrees in Mathematics and Computational Neuroscience, a major that I designed to study the brain from an interdisiplinary, quantitative approach with my mentors Flip Phillips, Tom O’Connell, and Michael Eckmann.
My approach relies on the tight interplay between neural modeling and psychophysical experiments: the models focus on dynamic interactions among multiple populations of neurons in different brain areas and obey constraints from neurophysiological data. I design experiments to generate and test hypotheses about how well mechanisms capture human behavior.
Projects
Robustness and Stability of
Human Heading Perception
How do humans reliably perceive self-motion in environments that contain moving objects?
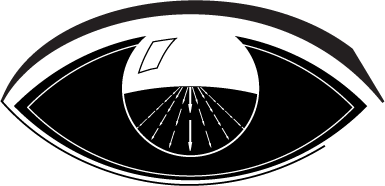
Even though moving objects may occupy large portions of the visual field for extended periods of time, our perception of self-motion (heading) remains robust and stable. Heading perception does not abruptly shift or fluctuate when moving objects cross our future path, an outcome that might be expected if the visual system globally integrated the motion generated by the object over short periods of time. The aim of this project is to uncover the mechanisms in our visual system that lead to such robust heading perception. Experiments conducted for this project have focused on properties of human heading perception in dynamic environments (e.g. in the presence of an object that retreats from the observer). Work has informed the development of The Competitive Dynamics model, a neural model of brain areas LGN, V1, MT, and MSTd, that generate robust, human-like heading estimates.
Object Motion Perception
during Self-Motion
How do we accurately perceive the motion of objects that move through the world?
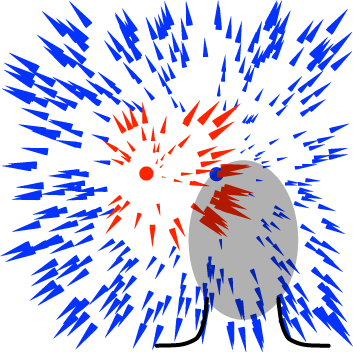
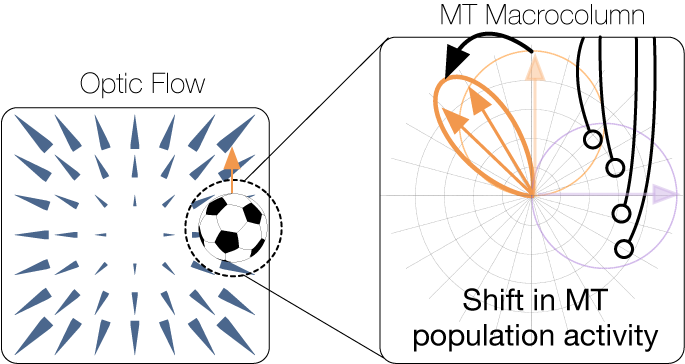
One reason that humans effectively interact with moving objects during self-motion is that we perceive trajectories of moving objects in much the same way, whether we're stationary or moving. This is remarkable considering that our self-motion may radically influence the object’s motion on the retina. A soccer ball that flies up and to the left may generate upward motion on the retina of a mobile observer, yet we do not notice a discrepancy because the brain factors out our self-motion. This project addresses the principles that underlie how the visual system integrates multiple signals experienced during self-motion (feedback and predictions, optic flow, vestibular signals, motor efference copies, etc.) to recover the motion of objects relative to the stationary world.
Read More
Detection of Moving Objects
How do we differentiate between stationary and independently moving objects during self-motion?
While luminance, color, and texture contrast may be used to differentiate between objects and their surroundings (figure-ground segregation), these properties can fail to be informative, such as when it comes to detecting the presence of camouflaged animals. In such scenarios, motion provides a powerful means to perform figure-ground segregation, as humans have little difficulty noticing an animal when sudden movement breaks its camoflague. Motion aids in detecting moving objects even during self-motion, when motion pervades the entire the visual field. For example, we effortlessly differentiate between moving and parked cars while driving. This project concerns the identification of neural mechanisms that enable humans to readily perceive the difference between earth-fixed objects and those that move independently from the observer during self-motion.
Read More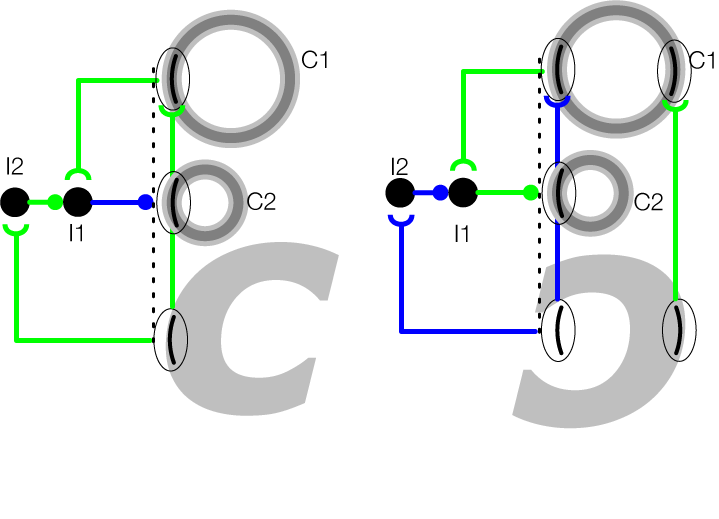
Object Boundary and Surface Coding
Why does a boundary belong to a figure and not its background?
Figure-ground segregation represents a fundamental competency performed by the visual system to perceive distinct objects at different depths from their background. This may occur through two complementary processes, one relating to object boundaries and the other relating to surfaces. First, the visual system must group boundaries belonging to the object, but not its background. So far, modeling work as a part of this project has leveraged a technique known as border-ownership (BO) coding, which occurs in primate visual cortex. BO is more informative than tradition approaches because, in addition to detecting edges, it associates them to the objects to which they belong. Second, the visual system must determine whether a region belongs to the interior or exterior of a shape. Work thus far has harnessed “skeleton” or medial axis representations of shapes at multiple spatial scales.
Read More