Robustness and Stability of Human Heading Perception
Competitive Dynamics Model
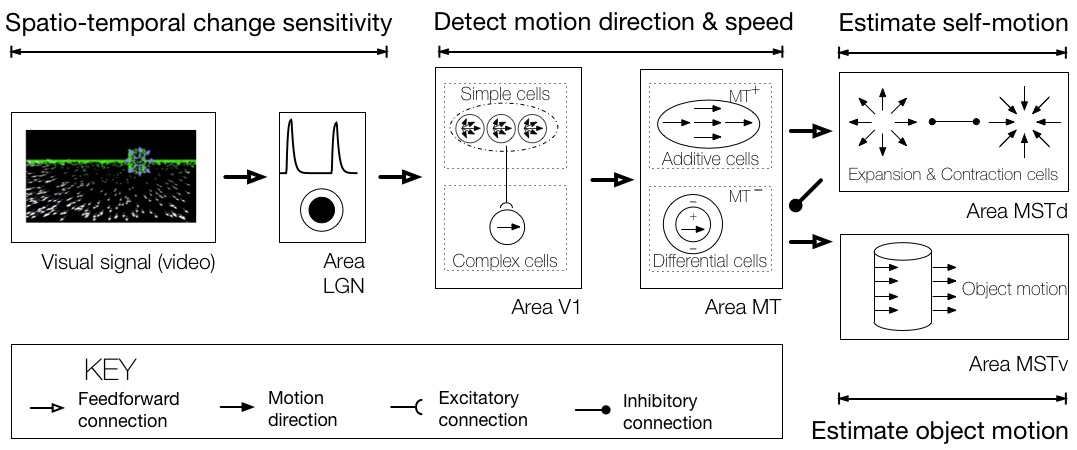
Humans and many other animals are notable in their ability to guide locomotion on the basis of vision. One rich source of visual information upon which observers can rely to perceive their self-motion is known as optic flow, the pattern of motion that appears on the retina over time as an animal moves through the world. Single neurons in a number of primate brain areas, including the dorsal superior medial temporal area (MSTd), exhibit sensitivity to optic flow patterns and are capable of extracting the observer’s direction of travel (heading). Human heading perception is not only accurate, but remarkably robust and stable over time. The robustness heading perception is particularly evident in dynamic environments that contain independently moving objects, in which case heading perception is biased by no more 1–3°. These biases are surprisingly small when one considers that the object may occupy large portions of the visual field (e.g. 100° or greater), and cross the observer’s future path, thereby occluding the region of the optic flow field that is most informative for heading direction.
The Competitive Dynamics Model is a dynamical neural model that I developed with collegues that captures the robustness of human heading perception. The model synthesizes neuroanatomical data from the primate dorsal stream, neurophysiological data on brain areas LGN, V1, MT, and MSTd, and psychophysical data from existing studies and experiments I designed that test specific model predictions. Neurons in area MSTd compete with one another in a recurrent network to determine heading. Each model neuron “votes” for the heading direction to which it is tuned and suppresses signals generated by other neurons in the network. At the population level, signals reflect the degree of confidence. Estimates are reliable and stable even in the presence of moving objects and during brief interruptions in the optic flow signal because model neurons accumulate evidence over time (Layton & Fajen, 2016). This is unlike other well-known biological models, which produce estimates that fluctuate wildly over time – sometimes by more than 50° in a matter of milliseconds. The model even makes errors that resemble those made by humans, accounts for attentional effects (Layton & Browning, 2012), and explains human perception along curved paths (Layton & Browning, 2014).
Optic flow
The optic flow from the simulation shown above contains three events: 1) self-motion along a ground plane toward a distant wall, 2) the presence of earth-fixed objects to either side of the observer’s path, 3) self-motion in the presence of an aerial moving object.
Model MSTd
The activity of model MSTd cells during phase 3, when the moving object appears. The horizontal axis indicates the preferred heading direction of MSTd cells tuned to radial expansion, and the vertical axis shows the response of each cell. In the simulation, heading is straight-ahead (center of the video container). The model heading estimate reflects the heading sensitivity of the MSTd cell that generates the activity peak. Throughout the simulation, heading estimates remain stable and close to the straight-ahead.
Model MSTv
The activity of model MSTv cells during phase 3, when the moving object appears. Cells in area MSTv only respond to the moving object, not the background. Responses reflect the world-relative direction of the aerial object (up and to the left) rather than that on the retina (upward).
A Framework to Test Neural Mechanisms
The model can be used as a framework, a “computational sandbox”, to quantitatively test the plausibility of different neural mechanisms. Different networks and neural circuits can be “plugged in” to test various hypotheses. For example, cells in primate MSTd are tuned to many types of motion patterns and interactions between these neural populations may affect heading in complex ways. I've used the model as a testbed to investigate how neural circuits and connectivity patterns (e.g. lateral inhibition, feedback) affect heading signals in different scenarios.
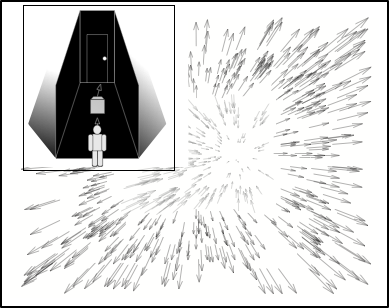
To illustrate the model’s capabilities as a framework, consider that area MSTd contains cells tuned to radially expanding or contracting optic flow. These patterns are encountered during forward and backward self-motion, respectively. The existence of both MSTd populations raises the question of whether they interact with one another or operate independently. To investigate this issue, I performed experiments with human subjects using the scenario depicted on the right, forward self-motion in the presence of an object that retreats from the observer. This scenario is useful for studying interactions in MSTd because it contains both expansion and contraction: radially expanding optic flow encompasses the visual field, except for the contraction on the interior of the retreating object.
I simulated the Competitive Dynamics model with different patterns of connectivity within MSTd to investigate what type of interactions yield heading estimates most consistent with human judgments. The video on the right shows a simulation of model MSTd in a scenario when human heading judgments are biased in the direction that the object retreats. The black curve shows the response of cells tuned to expansion, and the gray shows that of cells tuned to contraction. The heading signal generated by expansion cells is accurate initially (black peak centered), but the contraction cell response to the moving object influences the heading signal over time. As the retreating object clears the observer’s future path at the end of the video, MSTd heading signals tend toward those that occur during self-motion through a stationary environment, without moving objects. Please see our forthcoming article for more details.
Processing Optic Flow from Video

Model V1
Complex cells in model area V1 detect motion in the preferred direction from video. Above, the response of a V1 macro column is depicted with the eight joined “needles” (key shown on bottom right), where the length of each line segment indicates the response of the cell tuned to motion in the corresponding direction. Similar to V1 cells in cortex, direction selectivity is broadband and fairly coarse. This occurs due to the aperture problem, noise, aliasing in the video, and other factors.

Model MT
Cells in MT have larger receptive fields than V1 and integrate motion in the preferred direction over a wider area. This results in more reliable and accurate motion estimates.
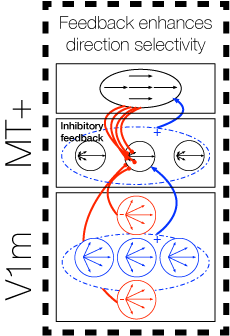
Model V1-MT Feedback Loop
Areas V1 and MT interact through a reciprocal feedback loop: MT cells integrate V1 motion signals and send feedback to suppress V1 cells tuned to inconsistent motion directions. Over time, this process reduces uncertainty and yields better motion signals in both V1 and MT.
Related Articles
-
Layton OW & Fajen BR (2016) Competitive Dynamics in MSTd: A Mechanism for Robust Heading Perception Based on Optic Flow. PLOS Computational Biology. 12(6).
-
Layton OW & Fajen BR (2016) The Temporal Dynamics of Heading Perception in the Presence of Moving Objects. Journal of Neurophysiology. 115(1).
-
Layton OW & Fajen BR (2016) Sources of bias in the perception of heading in the presence of moving objects: Object-based and border-based discrepancies. Journal of Vision. 16(1).
-
Layton OW & Browning NA (2014) A Unified Model of Heading and Path Perception in Primate MSTd. PLOS Computational Biology. 10(2).
-
Layton OW & NA Browning (2013) The Simultaneous Coding of Heading and Path in Primate MSTd. Neural Networks (IJCNN).
-
Layton OW & Browning NA (2012) Recurrent Competition Explains Temporal Effects of Attention in MSTd. Frontiers In Computational Neuroscience. 6(80).
-
Layton OW, Mingolla E, & Browning NA (2012) A Motion-Pooling Model of Visually-Guided Navigation Explains Human Behavior in the Presence of Independently Moving Objects. Journal of Vision.